|
||
|
|
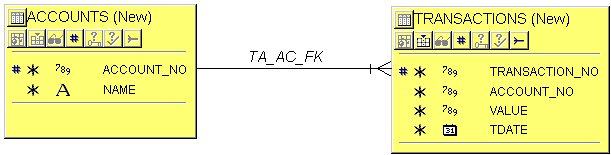
Denormalization, Normalization and PerformanceAs opposed to denormalization, the purpose of the normalization process is to reduce redundancy (same information stored more than once), and secure data integrity (that the database contains valid information).This is achieved by reducing large entities (large meaning a large number of attributes) into several other, lesser entities which together contains the same information, but without repeating it. This was demonstrated in the lesson on 3NF, where we removed a denormalized entity which contained a calculated attribute, and only accessed the TRANSACTIONS table whenever we wanted to know the balance of an account. The example was chosen deliberately: We are going to discuss it in this chapter. We’ll take a look at it again, comparing the two different approaches: Fig. 14a: Denormalization
Fig 14b: Normalization
It may seem obvious that a query on 14a will perform better than the same on 14b. This is due to the denormalization in the first figure. We are talking about reading one row as opposed to reading maybe several thousands. Performance vs. total performance. But how much better will it be? Will it be noticeable? Unless you have 100.000 + transactions for each account, it will hardly be noticeable. We are talking about indexed searches here: There will be an index on the ACCOUNT_NO column both in ACCOUNTS and TRANSACTIONS. We will almost certainly put an index on the TDATE column as well. So regardless of the volume in TRANSACTIONS, the database search algorithms will go straight on to the actual rows in the database. But I agree, performance may be an issue here with regards to how fast you can retrieve an accounts report from the database. That is: If you look at it isolated. But where do we get our information for the BALANCE column in 14a? We get it of course from one or more transactions. Which means that for each new transaction on any account, the corresponding balance has to be updated (or inserted for the first transaction). If a transaction is removed, we have to subtract the VALUE of the transaction from the corresponding BALANCE column. How much resources will that demand from the system? The answer is that the total performance of the system is most likely to be reduced by operating according to 14a. The only reason for doing this denormalization is if there are relatively few transactions, and a very high frequency of reporting accounts balances. But if there are relatively few transactions, then reporting according to 14b should not be resource intensive, should it? Is a denormalization really neccessary? Flexibility. No doubt is 14b more flexible than 14a. With 14a, you are restricted to report on a fixed number of periods. Anything outside the scope of periods is impossible, whereas in 14b, you have full flexibility down to each day. Actually, even more, A DATE format on TDATE should also contain the time of the transaction. If this is a real-time transaction system, you could, for any day, report on HH.MM.SS level. You could analyze the number of transactions, or sum of all transactions, let’s say per hour. You are totally free to report whatever. Changing the period definition. This will happen. I know. I have experienced it. When it comes to accounts, it is a fact that accountants wish to view the figures in relation to last year’s corresponding figures. They also have budgets, and want to see all accounts balances in relation to the corresponding budget figures. What must we do if they want to change the length of a period? In 14a we have to do a lot, in 14b we don’t do anything. Data that already have been calculated into BALANCES, need to be recalculated if we want to change the length of our reporting periods. That means deleting all rows in BALANCES, changing the period definitions in PERIODS, and re-read all transactions back in time, computing BALANCE and inserting the result into BALANCES. Until the job is done, we have no reporting functionality. Updating synchronization. Since we have to do a lot more in 14a each time a transaction
is inserted, updated or deleted, we must write an insert/update/delete
mechanism that is absolutely fool-proof. If not we will have
differences between TRANSACTIONS and BALANCES. The sum of all
transactions gives the right BALANCE for each account, so if it isn’t a
fool-proof mechanism, we will report wrong figures. This logic should never be placed in your application. When you design a database, you normally design it for a given application. When the database and the corresponding application are put to work, all is well. But after some time, others will find the database useful and they will wish to work on it, as well. We may have an invoicing system that we will use to insert transactions directly into the accounting system each time an invoice is generated. If the logic for maintenance of BALANCES is placed in the accounting applications, no BALANCES will be built for our sales accounts. Alternatively, the invoicing system must incorporate the maintenance logic. Then YOU have a maintenance logistic problem with your code. BTW, consider this guy’s problem, taken from a discussion forum: ?HI all,
I face a problem of partial commit . Like I written one stored procedure which inserts rows in two tables and after that Commit it. Things are working properly until one row was inserted in one table and not in the other with commit successful. I checked the log's there I got some oracle internal error . So can anybody tell how this partial commit is happened ? In what situations this will occur ?? I am glad it’s not me who has to take the responsibility for this….. To sum it up:Denormalization may solve one part of dealing with performance, but it creates possible performance problems in several other areas. Total performance impact must be evaluated. Furthermore, data integrity is at (high) risk.Rule: A clean, normalized database should always deliver good performance, as well as preserve data integrity. If you have a much higher demand on reporting functions, consider denormalization of your database into a separate data warehouse, which is periodically updated with summary information, preferably during night time, and leave your running database normalized for flexibility and data integrity. For such purposes, denormalization is a natural action to take. Actually, due to the current state of the art, it is sometimes necessary to consider. I do not like it, and you too know it's wrong, when you think about it... Also, read my section on database theory and practice. Hope you enjoyed this :-) |
Exclusive interviews with:
Free eBookSubscribe to my newsletter and get my ebook on Entity Relationship Modeling Principles as a free gift: What visitors say...
"I just stumbled accross your site looking for some normalization theory and I have to say it is fantastic.
Read more
Testimonials
I have been in the database field for 10+ years and I have never before come across such a useful site. Thank you for taking the time to put this site together." Mike, USA |
Theory & Practice DB Normalization Analysis Phase Database Keys DB Glossary Appl.Architecture Oracle DBA MySQL DBA SQL Server DBA Install Oracle Install SQL Server Proj.Management Oracle Constraint Programming Tips Database Normalization eBook: |
||
|
Copyright © www.databasedesign-resource.com /
All rights reserved. All information contained on this website is for informational purposes only. Disclaimer: www.databasedesign-resource.com does not warrant any company, product, service or any content contained herein. Return to top
The name Oracle is a trademark of Oracle Corporation. |
||